In this project, I wanted to move beyond simple correlations and ask a harder question:
Do Women, Business and the Law (WBL) legal reforms actually cause changes in real-world gender outcomes?
In particular, I focused on the eight WBL pillars:
Mobility
Workplace
Pay
Marriage
Parenthood
Entrepreneurship
Assets
Pension
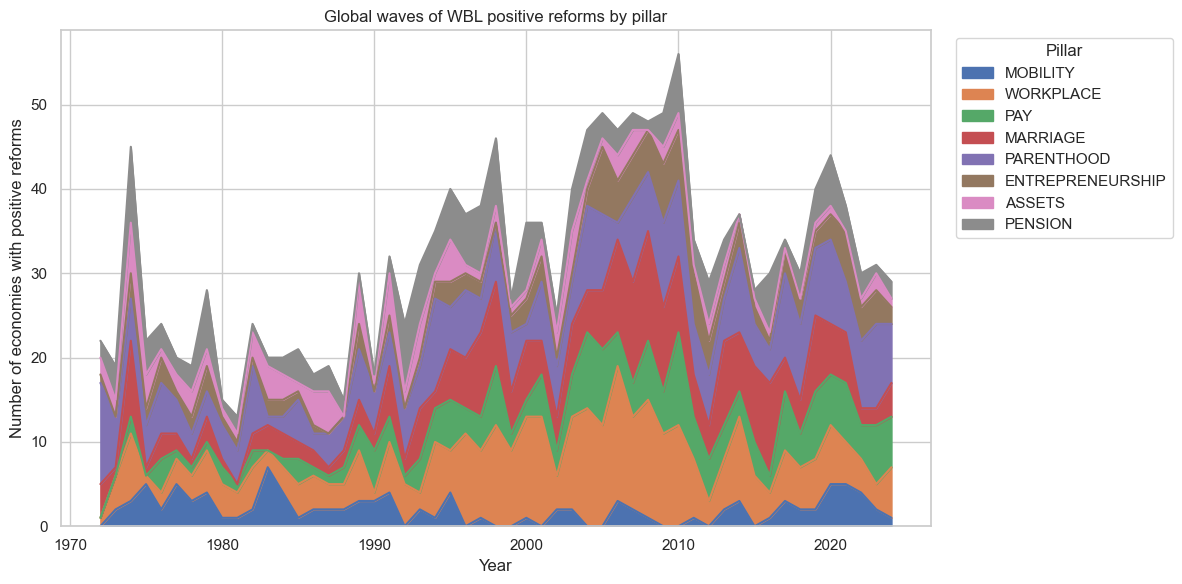
For each pillar, I mapped it to a set of World Development Indicators (WDI) that are plausibly downstream outcomes of legal changes in that area. Then I built a country–year panel that combines:
WBL reforms over time (1971–2024), and
Gender-related WDI outcomes over time.
Using this panel, I ran difference-in-differences (DiD) and event-study regressions to see whether positive WBL reforms are followed by statistically and substantively meaningful changes in gender outcomes.
Data WBL reforms
I started with the “WBL 1971–2024 Reforms Database”, which is an economy–year–indicator dataset that records when each country adopted legal changes in each WBL pillar. For each record, I have:
Economy name
WBL indicator or pillar (Mobility, Workplace, etc.)
Report year
Type of reform (Positive, Negative, etc.)
I restricted attention to positive reforms. For each country and each pillar, I computed the first year in which a positive reform occurred. I’ll call that the “first positive reform year” for that pillar in that country.
I then matched the WBL economies to ISO3 country codes using the WBL panel file, with a bit of manual name cleaning where needed (for example, converting “Viet Nam” to “Vietnam”) so I could link them to the WDI data.
WDI outcomes panel
To get outcome variables that are not mechanically tied to WBL scores, I constructed my own outcome panel from the World Development Indicators. I designed a mapping from WBL pillars to WDI indicators, focusing on measures that are directly relevant to women’s labor participation, health, empowerment, and assets.
Here is the mapping I used:
Mobility
Female labor force participation rate (% of female population)
Female labor force participation rate to male rate ratio
Female employment-to-population ratio (%)
Workplace
Female unemployment rate (%)
Vulnerable employment, female (% of female employment)
Pay
Wage and salaried workers, female (% of female employment)
Self-employed workers, female (% of female employment)
Employers, female (% of female employment)
Marriage
Child marriage before age 18 (% of women)
Adolescent fertility rate (births per 1,000 women ages 15–19)
Intimate partner violence, women 15–49 in the last 12 months (%)
Parenthood
Births attended by skilled health staff (%)
Maternal mortality ratio (per 100,000 live births)
Total fertility rate (births per woman)
Entrepreneurship
Firms with female ownership (% of firms)
Female share of senior and middle management (% of management)
Women in national parliament (% of seats)
Assets
Ratio of girls to boys in combined primary and secondary enrollment
Female adult literacy rate (%)
Female life expectancy at birth (years)
Pension
Female population 65+ as a percentage of total female population
(I also tried to include female life expectancy at 65 and female employment 55–64, but they did not always survive into the final estimations.)
To actually build the panel, I:
Pulled the WDICSV file and filtered it to these indicator codes.
Reshaped the data from wide (one row per country–indicator, many year columns) to long (country, year, indicator, value).
Pivoted that into a country–year panel where each selected indicator is a column.
Filtered to countries that have a non-missing income group in the WDI country metadata (to restrict to “real” economies).
Saved the final panel as wbl_outcomes_panel.csv with columns like:
country_code (ISO3)
year
the WDI outcomes listed above.
This gives me a panel covering up to 215 economies over several decades (roughly 1960–2024, depending on the series), with about 20 distinct outcome variables.
Code
import pandas as pdfrom pathlib import PathWDI_DIR = Path("") # change if neededindicator_map = {# MOBILITY (MOB_)"mobility_lfpr_female_pct": "SL.TLF.CACT.FE.ZS","mobility_lfpr_female_to_male_ratio": "SL.TLF.CACT.FM.ZS","mobility_employment_to_pop_female_pct": "SL.EMP.TOTL.SP.FE.ZS",# WORKPLACE (WKP_)"workplace_unemployment_female_pct": "SL.UEM.TOTL.FE.ZS","workplace_vulnerable_employment_female_pct": "SL.EMP.VULN.FE.ZS","workplace_share_women_nonag_wage_employment_pct": "SL.EMP.INSV.FE.ZS",# PAY (PAY_)"pay_wage_salaried_workers_female_pct": "SL.EMP.WORK.FE.ZS","pay_self_employed_female_pct": "SL.EMP.SELF.FE.ZS","pay_employers_female_pct": "SL.EMP.MPYR.FE.ZS",# MARRIAGE (MAR_)"marriage_child_marriage_before18_pct": "SP.M18.2024.FE.ZS","marriage_adolescent_fertility_rate_15_19": "SP.ADO.TFRT","marriage_ipv_women_15_49_last12m_pct": "SG.VAW.1549.ZS",# PARENTHOOD (PAR_)"parenthood_births_attended_by_skilled_staff_pct": "SH.STA.BRTC.ZS","parenthood_maternal_mortality_ratio_per_100k": "SH.STA.MMRT","parenthood_total_fertility_rate_births_per_woman": "SP.DYN.TFRT.IN",# ENTREPRENEURSHIP (ENT_)"entrepreneurship_firms_with_female_ownership_pct": "IC.FRM.FEMO.ZS","entrepreneurship_female_share_senior_mgmt_pct": "SL.EMP.SMGT.FE.ZS","entrepreneurship_women_in_parliament_pct": "SG.GEN.PARL.ZS",# ASSETS (AST_) – human-capital / capability proxies"assets_ratio_girls_to_boys_primary_secondary_enrol": "SE.ENR.PRSC.FM.ZS","assets_adult_female_literacy_pct": "SE.ADT.LIT.FE.ZS","assets_life_expectancy_female_years": "SP.DYN.LE00.FE.IN",# PENSION (PEN_) – ageing / old-age security proxies"pension_share_population_65plus_female_pct": "SP.POP.65UP.FE.ZS","pension_life_expectancy_at_65_female_years": "SP.DYN.LE65.FE.IN","pension_employment_to_pop_female_55_64_pct": "SL.EMP.5564.SP.FE.ZS",}indicator_map = {k: v for k, v in indicator_map.items() if v}wdi_data_path = WDI_DIR /"WDICSV.csv"wdi_country_path = WDI_DIR /"WDICountry.csv"wdi_raw = pd.read_csv(wdi_data_path)countries_meta = pd.read_csv(wdi_country_path)year_cols = [c for c in wdi_raw.columns if c.isdigit()]codes_of_interest =set(indicator_map.values())wdi_filtered = wdi_raw[wdi_raw["Indicator Code"].isin(codes_of_interest)].copy()wdi_long = wdi_filtered.melt( id_vars=["Country Name", "Country Code", "Indicator Code"], value_vars=year_cols, var_name="Year", value_name="value",)wdi_long["Year"] = pd.to_numeric(wdi_long["Year"], errors="coerce").astype("Int64")panel = ( wdi_long .pivot_table(index=["Country Code", "Year"], columns="Indicator Code", values="value") .reset_index())code_to_col = {code: col for col, code in indicator_map.items()}panel = panel.rename(columns=code_to_col)valid_country_codes = countries_meta[countries_meta["Income Group"].notna()]["Country Code"]panel = panel[panel["Country Code"].isin(valid_country_codes)]panel = panel.rename(columns={"Country Code": "country_code", "Year": "year"})target_cols =list(indicator_map.keys())cols_in_panel = [c for c in target_cols if c in panel.columns]final_cols = ["country_code", "year"] + cols_in_panelpanel_final = panel[final_cols].sort_values(["country_code", "year"]).reset_index(drop=True)output_path = Path("wbl_outcomes_panel.csv")print(panel_final)panel_final.to_csv(output_path, index=False)print("Saved", output_path.resolve())print("Columns:", panel_final.columns.tolist())
Indicator Code country_code year mobility_lfpr_female_pct \
0 ABW 1960 NaN
1 ABW 1961 NaN
2 ABW 1962 NaN
3 ABW 1963 NaN
4 ABW 1964 NaN
... ... ... ...
13970 ZWE 2020 59.525
13971 ZWE 2021 60.121
13972 ZWE 2022 59.769
13973 ZWE 2023 59.677
13974 ZWE 2024 59.618
Indicator Code mobility_lfpr_female_to_male_ratio \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 83.771955
13971 83.832060
13972 83.350533
13973 83.670293
13974 83.710808
Indicator Code mobility_employment_to_pop_female_pct \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 54.467
13971 54.194
13972 53.457
13973 54.411
13974 54.498
Indicator Code workplace_unemployment_female_pct \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 8.497
13971 9.858
13972 10.562
13973 8.824
13974 8.587
Indicator Code workplace_vulnerable_employment_female_pct \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 76.404615
13971 76.507140
13972 76.707355
13973 76.540949
13974 NaN
Indicator Code pay_wage_salaried_workers_female_pct \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 21.667887
13971 21.602362
13972 21.461752
13973 21.575322
13974 NaN
Indicator Code pay_self_employed_female_pct pay_employers_female_pct ... \
0 NaN NaN ...
1 NaN NaN ...
2 NaN NaN ...
3 NaN NaN ...
4 NaN NaN ...
... ... ... ...
13970 78.332150 1.927498 ...
13971 78.397675 1.890534 ...
13972 78.538211 1.830856 ...
13973 78.424678 1.883729 ...
13974 NaN NaN ...
Indicator Code marriage_ipv_women_15_49_last12m_pct \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 NaN
13971 NaN
13972 NaN
13973 NaN
13974 NaN
Indicator Code parenthood_births_attended_by_skilled_staff_pct \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 NaN
13971 NaN
13972 NaN
13973 NaN
13974 NaN
Indicator Code parenthood_maternal_mortality_ratio_per_100k \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 380.0
13971 446.0
13972 368.0
13973 358.0
13974 NaN
Indicator Code parenthood_total_fertility_rate_births_per_woman \
0 4.567
1 4.422
2 4.262
3 4.107
4 3.940
... ...
13970 3.754
13971 3.765
13972 3.767
13973 3.724
13974 NaN
Indicator Code entrepreneurship_firms_with_female_ownership_pct \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 NaN
13971 NaN
13972 NaN
13973 NaN
13974 NaN
Indicator Code entrepreneurship_female_share_senior_mgmt_pct \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 NaN
13971 28.151
13972 29.273
13973 33.359
13974 NaN
Indicator Code entrepreneurship_women_in_parliament_pct \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 31.851852
13971 31.851852
13972 30.566038
13973 30.681818
13974 28.089888
Indicator Code assets_ratio_girls_to_boys_primary_secondary_enrol \
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
13970 NaN
13971 NaN
13972 NaN
13973 NaN
13974 NaN
Indicator Code assets_life_expectancy_female_years \
0 67.459
1 67.394
2 67.922
3 68.389
4 68.902
... ...
13970 63.747
13971 62.289
13972 64.544
13973 65.013
13974 NaN
Indicator Code pension_share_population_65plus_female_pct
0 3.344494
1 3.364245
2 3.395218
3 3.432388
4 3.491608
... ...
13970 3.999797
13971 4.048161
13972 4.087006
13973 4.124704
13974 4.132289
[13975 rows x 22 columns]
Saved /Users/prakash/projects/womens_equality/wbl_outcomes_panel.csv
Columns: ['country_code', 'year', 'mobility_lfpr_female_pct', 'mobility_lfpr_female_to_male_ratio', 'mobility_employment_to_pop_female_pct', 'workplace_unemployment_female_pct', 'workplace_vulnerable_employment_female_pct', 'pay_wage_salaried_workers_female_pct', 'pay_self_employed_female_pct', 'pay_employers_female_pct', 'marriage_child_marriage_before18_pct', 'marriage_adolescent_fertility_rate_15_19', 'marriage_ipv_women_15_49_last12m_pct', 'parenthood_births_attended_by_skilled_staff_pct', 'parenthood_maternal_mortality_ratio_per_100k', 'parenthood_total_fertility_rate_births_per_woman', 'entrepreneurship_firms_with_female_ownership_pct', 'entrepreneurship_female_share_senior_mgmt_pct', 'entrepreneurship_women_in_parliament_pct', 'assets_ratio_girls_to_boys_primary_secondary_enrol', 'assets_life_expectancy_female_years', 'pension_share_population_65plus_female_pct']
Treatment definition and panel construction Treatment indicator (for DiD)
For each country and each WBL pillar, I defined the “treatment timing” as the first year the country adopted a positive reform in that pillar.
Then I defined a treatment dummy that starts two years after that first positive reform. The idea is to allow time for the law to be implemented and for outcomes to react.
Formally, for each country, pillar, and year I set:
Treated = 1 if the year is at least first positive reform year + 2
Treated = 0 otherwise
If a country never has a positive reform in that pillar, its treatment dummy is 0 in all years.
I merged these treatment indicators into the WDI outcomes panel so that for each country–year, I know which pillars (if any) are in the “post-reform” state.
Event time (for dynamic analysis)
For the event-study part, I also defined an “event time”:
Event time = year minus the first positive reform year for that pillar.
I restricted event time to a window from 10 years before the first reform to 10 years after (from −10 to +10). I then constructed a dummy variable for each event time value in that window.
In the event-study regressions, I treated the year just before reform (event time −1) as the baseline and estimated deviations relative to that year.
Note: For the event study, I only used countries that ever had a positive reform in the pillar in question, because I need a defined first reform year to construct event time.
For each WBL pillar and each associated WDI outcome, I ran a two-way fixed-effects difference-in-differences regression.
The idea is:
The outcome is one of the WDI indicators (for example, the female labor force participation rate).
The key regressor is the treatment dummy for the relevant pillar (for example, Mobility), which switches from 0 to 1 after the lagged reform date.
I also include:
Country fixed effects (one dummy per country), and
Year fixed effects (one dummy per year).
Country fixed effects remove time-invariant differences between countries (for example, geography, legal tradition, culture that does not change quickly). Year fixed effects remove global shocks (for example, world recessions, global health trends) that affect all countries in a given year.
I estimated these models using ordinary least squares with:
Country and year dummies for the fixed effects, and
Clustered standard errors at the country level to account for serial correlation within countries over time.
The coefficient on the treatment dummy is my main “causality metric” for that pillar–outcome combination: it is the average change in the outcome associated with entering the post-reform state, relative to the path of countries that have not yet reformed, controlling for country and year effects.
Event-study analysis
To look at dynamics and to check the key assumption of parallel trends, I also ran event-study regressions.
For each pillar and outcome, I regressed the outcome on:
A set of dummies for event times from −10 to +10, excluding event time −1, which I treat as the baseline
Country fixed effects
Year fixed effects
I again clustered standard errors by country.
For each event time, I get a coefficient that tells me the average difference in the outcome at that event time relative to the year just before reform, after controlling for country and year effects.
This gives me a dynamic profile: how the outcome behaves in the years leading up to the first reform, and in the years after. It is also a key diagnostic: under a clean difference-in-differences design, I would ideally see flat, statistically insignificant coefficients for the pre-reform years.
In this implementation, the event-study sample is restricted to ever-treated countries for that pillar. So these event-time profiles show how treated countries evolve around their first reform, not explicitly treated-minus-control trajectories.
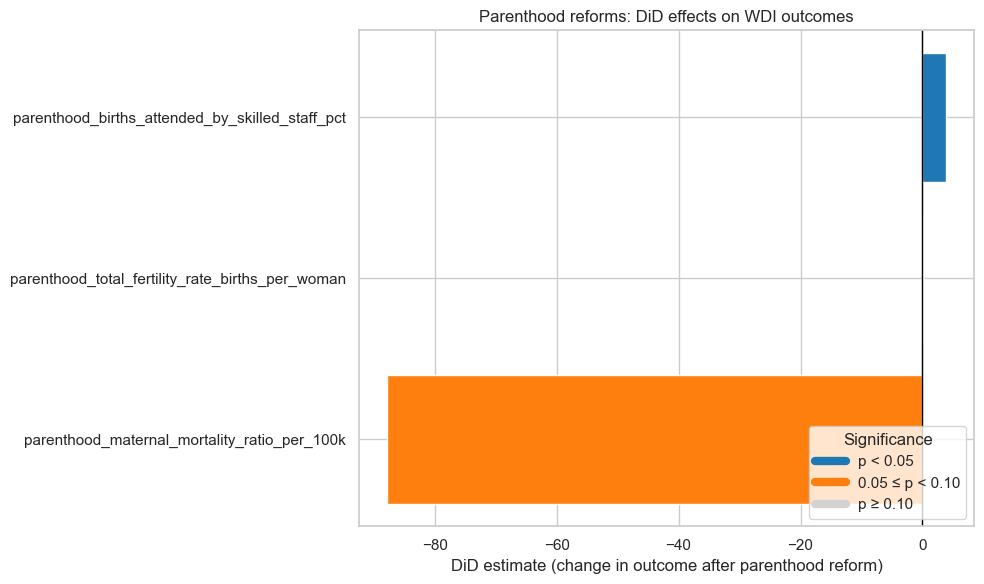
Main results Static DiD: pillar–outcome estimates
I ran static DiD regressions for 20 pillar–outcome pairs where I had enough data. Here is the big-picture summary:
Only one coefficient is statistically significant at the 5 percent level.
Three coefficients are significant at the 10 percent level.
All of the meaningful signals come from the Parenthood pillar.
If I do a simple multiple-testing correction across all regressions, none of the coefficients remain significant at conventional levels.
So, statistically, the evidence for large, clean causal effects is weak. Still, it’s useful to see where the signal is strongest. That is clearly in the parenthood-related outcomes.
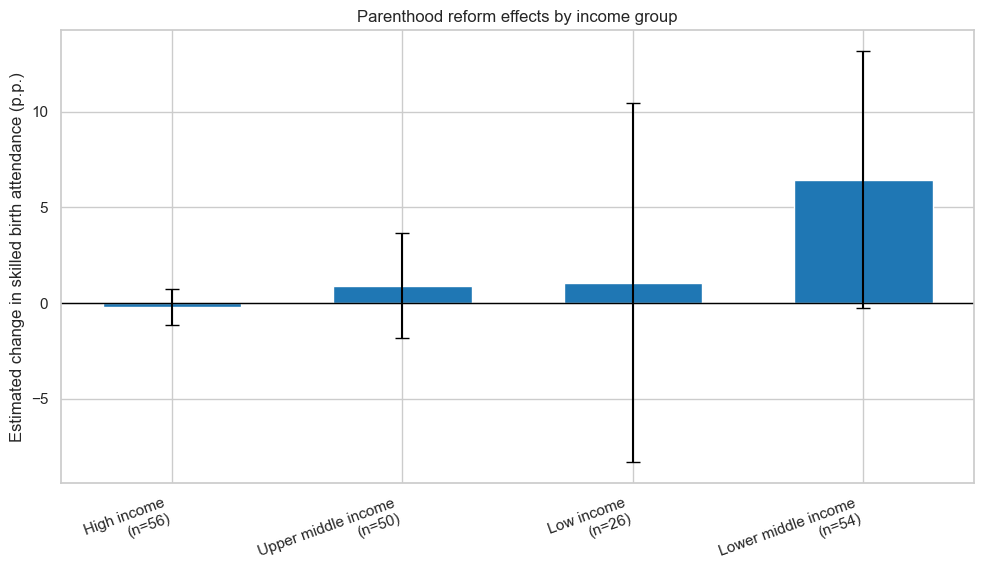
Parenthood reforms
For the Parenthood pillar, I looked at three outcomes:
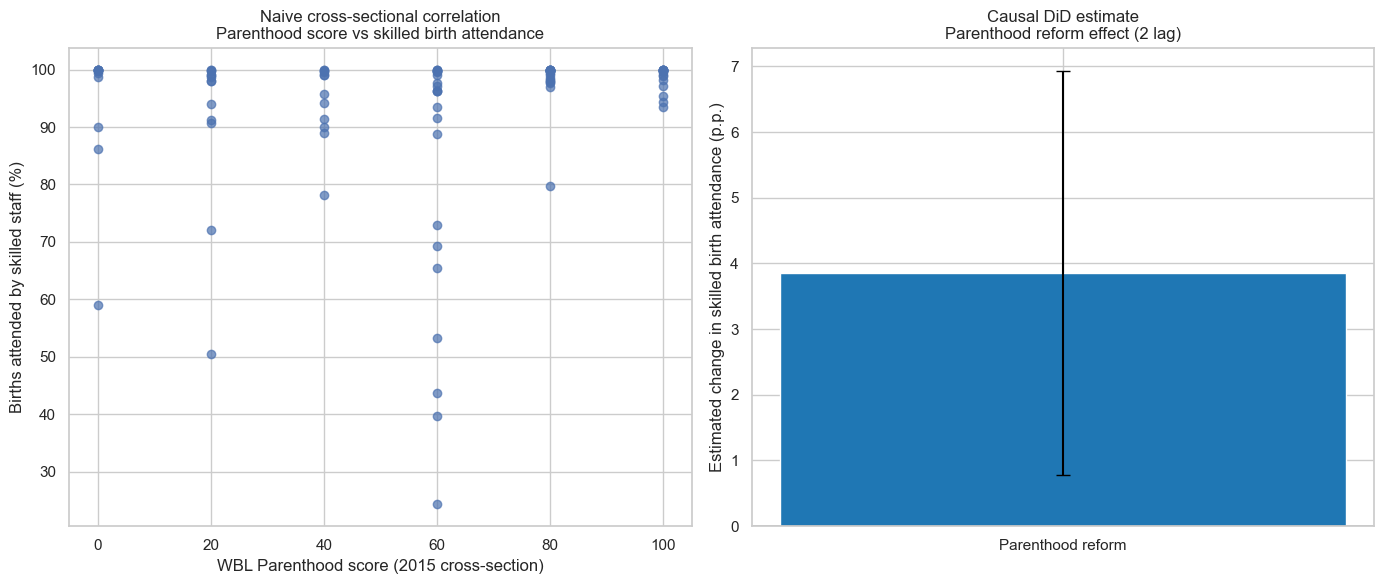
Births attended by skilled health staff (% of total)
The DiD estimate is around +4 percentage points.
The standard deviation of this outcome is about 20 percentage points, so this effect is about one fifth of a standard deviation.
The p-value is around 0.013.
Sample size is about 3,000 country–year observations across roughly 200 economies.
Interpretation: After a positive parenthood reform (with a two-year lag), countries tend to see a noticeable increase in the share of births attended by skilled staff.
Maternal mortality ratio (deaths per 100,000 live births)
The DiD estimate is around −88 deaths per 100,000.
The standard deviation is around 400, so this is about a quarter of a standard deviation.
The p-value is around 0.09 (marginal at 10 percent, not at 5).
Sample size is around 7,500 observations across about 190 economies.
Interpretation: There is suggestive evidence that parenthood reforms are associated with reductions in maternal mortality, but the estimate is noisy.
Total fertility rate (births per woman)
The DiD estimate is around +0.16 births per woman.
The standard deviation is about 2, so this is roughly 0.08 standard deviations.
The p-value is about 0.05.
Sample size is around 13,700 observations across more than 200 economies.
Interpretation: Parenthood reforms are associated with a small increase in fertility. Whether that is good or bad depends on context; higher fertility might reflect improved survival, shifting preferences, or other factors.
Taken together, these results suggest that the Parenthood pillar is the one place where I see moderate, statistically fragile but substantively meaningful associations between legal reforms and health-related outcomes.
Other pillars
For the other seven pillars, the DiD estimates are generally:
Small relative to the variation in the outcome, and
Not statistically significant at the 5 percent level.
Some highlights:
Mobility (labor force participation and employment-to-population): coefficients are modest and p-values are large; I do not see clear jumps in aggregate labor participation after mobility reforms.
Workplace (female unemployment, vulnerable employment): estimates are close to zero, with very high p-values.
Pay (composition of female employment across wage work, self-employment, employer status): point estimates are modest (less than 1 percentage point in absolute value), with p-values ranging from about 0.2 to 0.7.
Entrepreneurship (female firm ownership, women in management, women in parliament):
Female firm ownership: around +2.4 percentage points, but not significant.
Female share of senior management: around −1.4 points, marginally insignificant.
Women in parliament: small, noisy positive effect.
Assets (education ratios, female literacy, female life expectancy): no strong signals; estimates are small and imprecise.
Pension (female elderly population share): around +0.4 percentage points, not significant.
So, in this specification, I do not see compelling evidence that most WBL pillars have large, immediate, average effects on my chosen WDI outcomes at the macro level.
Dynamic results and assumption checks
The event-study results are critical for understanding whether the difference-in-differences assumptions are plausible.
Pre-trends
For each pillar and outcome, I looked at the event-time coefficients for the 10 years before the first reform (event times −10 to −2).
What I found is that these pre-reform coefficients are often not flat and frequently statistically significant. In fact:
For most pillar–outcome pairs, a large fraction of the pre-reform event-time coefficients are individually significant at the 5 percent level.
In many cases, treated countries show strong trends in the outcome long before the first legal reform is recorded.
This suggests that the key difference-in-differences assumption, “in the absence of the reform, treated and not-yet-treated countries would have followed similar trends,” is quite fragile for many outcomes.
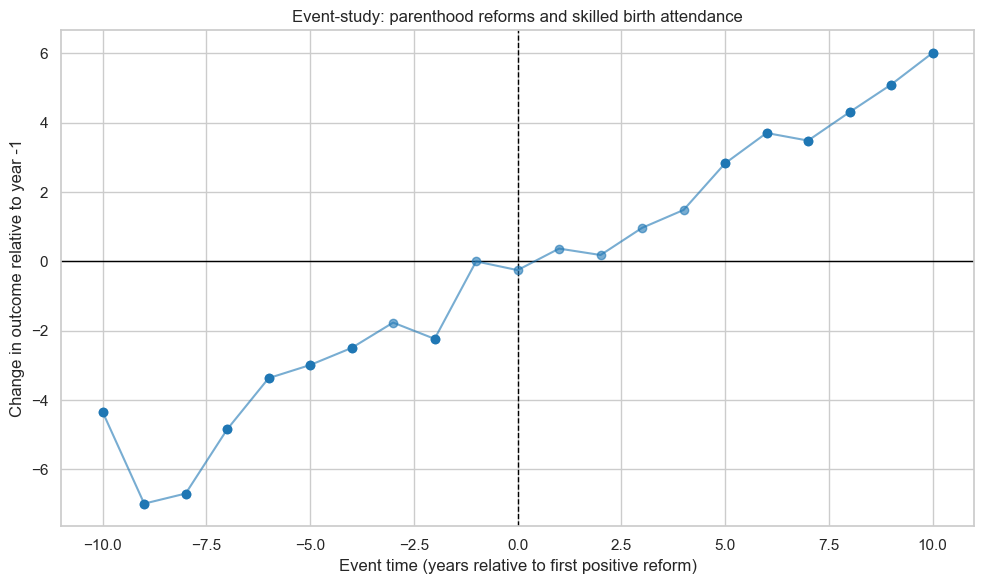
Example: Parenthood and skilled birth attendance
For births attended by skilled health staff:
In the pre-reform period, the event-time coefficients are mostly negative and significant, implying that 6–10 years before the first parenthood reform, the share of skilled birth attendance is significantly lower than in the year right before the reform. Over time, these negative coefficients move toward zero as the country improves.
In the post-reform period, the coefficients are positive and significant, gradually rising to several percentage points above the pre-reform baseline.
The picture that emerges is not a sharp jump at the reform date, but a smooth upward trend over many years, with the legal reform occurring somewhere in the middle of that trajectory.
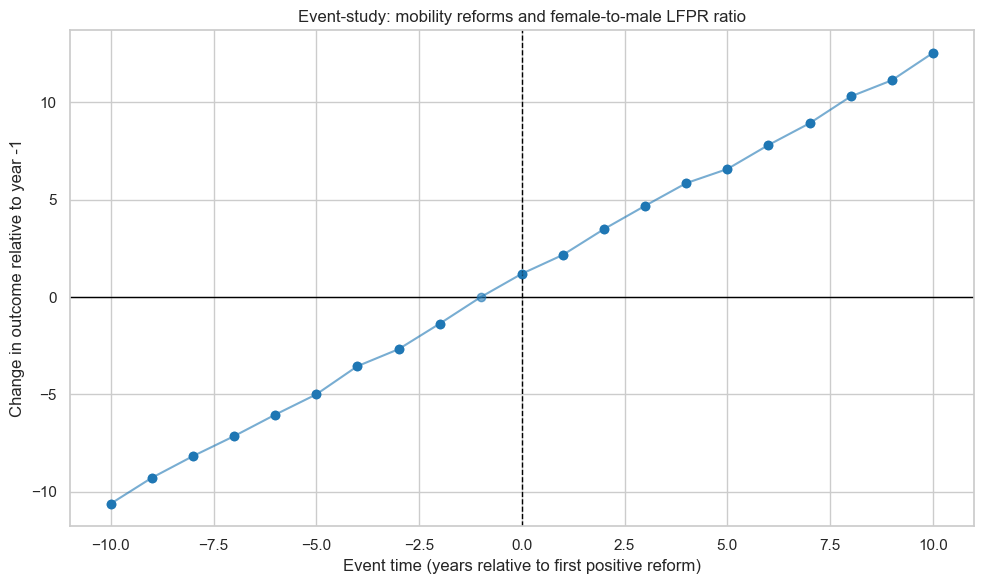
Example: Mobility and relative female labor force participation
For the ratio of female to male labor force participation:
Pre-reform coefficients are strongly negative and significant, meaning that many years before the first mobility reform, the female-to-male participation ratio is far below the level observed in the year before reform.
Post-reform coefficients are strongly positive, suggesting that over time the ratio rises above the pre-reform baseline.
Again, this looks like a long-run trend in women’s labor market participation, not a sudden shift triggered solely by the legal change.
Interpretation, limitations, and how “causal” this is What I can say
With the panel I built and the methods I used, I can say:
I constructed a multi-decade, multi-country panel combining WBL positive reforms with a curated set of WDI outcomes.
I applied standard two-way fixed-effects DiD and event-study models.
Under the usual assumptions (especially parallel trends), the DiD coefficients can be interpreted as causal effects of WBL reforms on the outcomes.
In practice, I find:
Some evidence that parenthood-related reforms are followed by improvements in maternal health outcomes (higher skilled birth attendance, lower maternal mortality), and a small increase in fertility.
Much weaker, mostly non-significant evidence of large macro-level effects for reforms in other pillars on my chosen outcomes.
Key limitations
However, there are several important caveats:
Parallel trends are shaky. The event-study profiles show that many treated countries are already on strong upward or downward trends long before the first reform. This undermines the idea that we can cleanly compare treated and not-yet-treated countries as if they were on parallel paths before the law change.
Staggered adoption TWFE issues. I used a standard two-way fixed-effects specification with staggered adoption. Recent econometric literature has shown that this design can be biased when treatment effects vary over time, which is very likely in this context.
Event study only within treated units. My event-study implementation tracks treated countries around their own reform dates; it does not explicitly construct an “event-time” comparison with never-treated or later-treated controls. So the pre-trends I see for treated units are informative but not a full treated-minus-control event study.
Potential endogeneity of reforms. It is very plausible that reforms are not random; they may be passed because outcomes are improving or because of underlying social and political changes that also affect outcomes. Fixed effects and year effects remove some of this, but not all time-varying confounders.
Measurement and data limitations.
Some WDI series are sparse or noisy, which affects the stability of regression estimates.
Legal changes are recorded at annual resolution and do not capture enforcement intensity or subnational variation.
Multiple testing. I run many regressions across pillars and outcomes. Once I account for multiple comparisons, very few results remain statistically strong.
If I were to strengthen the causal claims further, I would:
Switch from a simple two-way fixed-effects DiD to modern estimators for staggered adoption (for example, Callaway–Sant’Anna or Sun–Abraham).
Tighten the event-study window (for example, to −5 to +5 years) and formally test whether the pre-reform coefficients are jointly zero in a cleaner treated-vs-control event-study design.
Add time-varying covariates like log GDP per capita, democracy scores, education levels, or public health spending to absorb some of the broader trend components.
Explore differential effects by income group, region, or baseline WBL level to see whether reforms matter more in certain contexts.
Run placebo tests with fake reform dates to see if I still pick up “effects” when nothing should be happening.